An Introduction to Large Language Models (LLMs)
This week, I decided to explore LLMs more deeply. While I’ve worked on projects that use them before, it was always more about meeting specific project requirements without fully understanding how they work. I wanted to explain how you can understand LLMs in a simple way.
What is LLM(Large Language Model)?
LLMs are scaled up versions of Transformers architecture, consisting of millions or billions of parameters. Most modern LLMs are decoder-only models, trained on massive amounts of data, with the primary training objective being ‘next token prediction.’
Example:
- “It is raining outside, so i will take my _____”
LLMs (Large Language Models) work by predicting the next word (or token) in a sequence.
A token is a unit of text that an AI model processes. Tokens can be words, subwords and tokenization is the process of breaking down text into tokens. AI models don’t read sentences like humans, AI models process these tokens one by one to understand and generate text.
Let’s try tokenization with tiktoken library.
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4-0125")
encoded_text = enc.encode("tiktoken is great!")
encoded_text
# [83, 1609, 5963, 374, 2294, 0]
[enc.decode([token]) for token in encoded_text]
# ['t', 'ik', 'token', ' is', ' great', '!']
enc.decode([83, 1609, 5963, 374, 2294, 0])
# 'tiktoken is great!'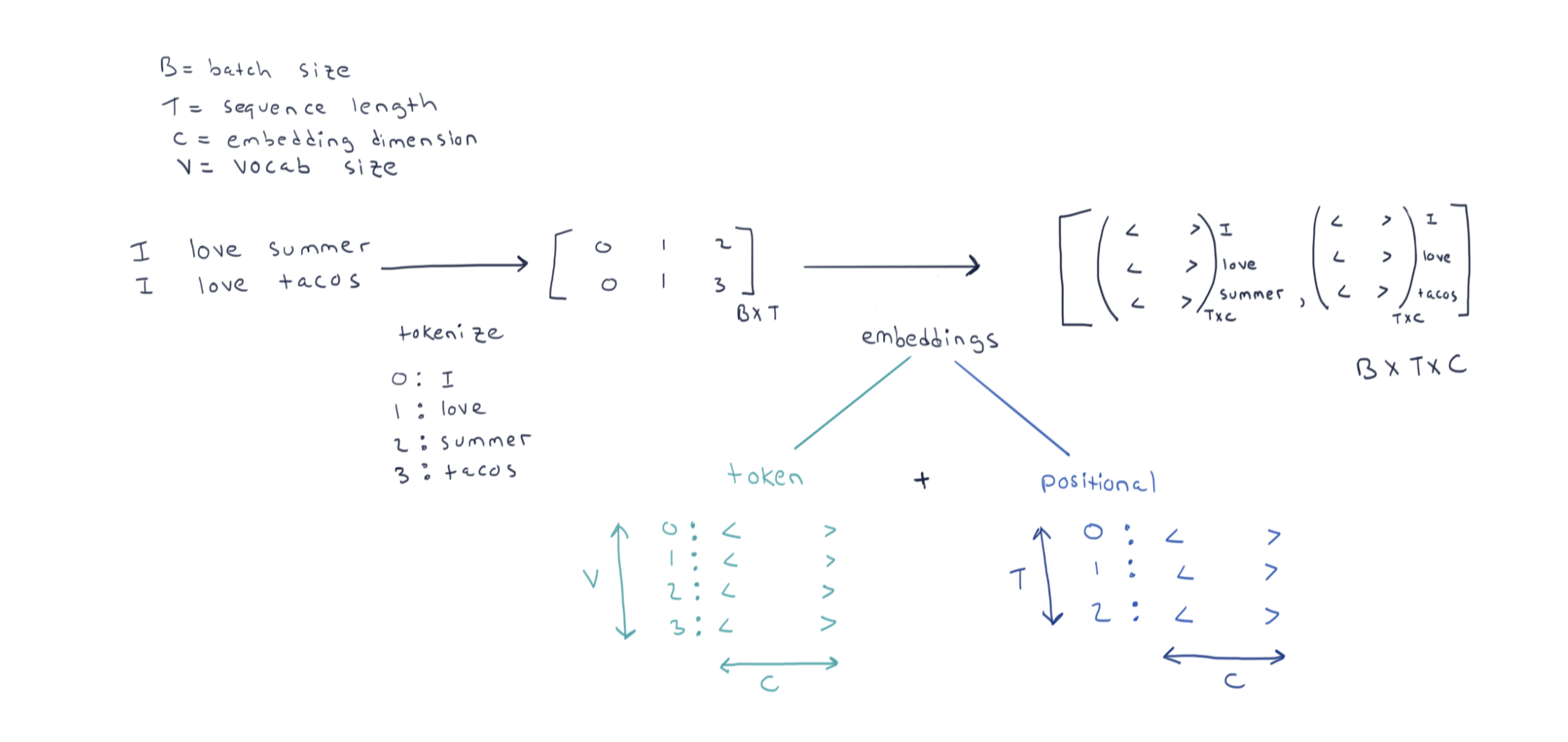
Pretraining
Large Language Models (LLMs) are trained on vast amounts of data.
Training, also called pretraining, is the process of
teaching the network to recognize patterns in the input data.
Essentially, we are taking large chunks of internet text and compressing
them into knobs the model can tune, known as weights and biases (
collectively called parameters).
Transformers
It all started with Attention is All you need. It introduced the Transformer architecture, a more efficient amd pwerful way of building language models.
Before processing, words are converted into numerical vectors called embeddings. These embeddings capture semantic information, meaning that similar words are represented by similar vectors in a high dimensional space.
Transformers use attention mechanisms, specifically self-attention. While attention had been used in previous models, it only read sequences word by word.Transformers can consider the entire input sequence at once. This allows the model to focus on different parts of input when generating each part of the output, much like how human understands language by considering the context of sequence or paragraph.
For example, in the sentence “This cat sat on mat because it was tired”, the word “it” refers to “cat”. Self-attention helps the model establish this connection by assigning higher weights to related words, enabling it to understand that “it” refers to “cat” and not “mat”.
By utilizing self-attention, transformers can process entire sequences of data in parallel rather than one element at a time, making training faster and more efficient when leveraging GPUs.
Fine-tuning
After pretraining, the model may need to be adapted for specific tasks and fin-tuning is the process of adjusting a pretrained model to have a specific output for your task. During fine-tuning models parameters - the weights and biases are adjusted slightly to improve performance.
Inference
After training and fine-tuning, the model is ready for inference - prcocess of making predictions or generating outputs from new inputs. During inference, the model applies what it learned to produce responses. Modern language models can perform complex reasoning tasks using techniques like chain of thought. This involves the model generating intermediate reasoning steps before arriving at a final answer.
Let’s dive into some code using the OpenAI library and generate a response from a language model. It creates a chat completion request with a question about the main characters of the Ramayana, using the GPT-3.5 model.
from openai import OpenAI
client = OpenAI()
chat_completion = client.chat.completions.create(
model="gpt-3.5-turbo-0125",
messages=[
{"role": "user", "content": "Who are the main characters from Ramayana?."},
],
)
response = chat_completion.choices[0].message.content
print(response)#Sample output:
The main characters from the Hindu epic Ramayana are:
1. Lord Rama - The Prince of Ayodhya and the protagonist of the epic. He is known for his virtues, righteousness, and courage.
........OpenAI-Compatible LLM Inference
How to use an OpenAI-compatible LLM for inference with the TOGETHER_API_KEY
from openai import OpenAI
import os
client = OpenAI(api_key=os.environ.get("TOGETHER_API_KEY"), base_url="https://api.together.xyz/v1")
chat_completion = client.chat.completions.create(
model="META-LLAMA/LLAMA-3-70B-CHAT-HF",
messages=[
{"role": "user", "content": "Who are the main characters from Ramayana?."},
],
)
response = chat_completion.choices[0].message.content
print(response)Above example showcases how to interact with a different LLM API while still following a similar structure to OpenAI’s API.
#Sample Output:
The main characters from the ancient Indian epic, Ramayana, are:
**1. Rama** (also known as Ramachandra): The hero of the story, Rama is the prince of Ayodhya and the seventh avatar (incarnation) of Lord Vishnu. He is known for his bravery, loyalty, and adherence to duty.
Now, we will explore how to structure your output using simple OpenAI query that asks for the main characters of the Ramayana, along with their skills, weapons, and fun facts. The initial output is unstructured, but for greater control over the format, we use the Instructor library to define a specific structure for the response.
from openai import OpenAI
client = OpenAI()
chat_completion = client.chat.completions.create(
model="gpt-3.5-turbo-0125",
messages=[
{"role": "user", "content": "Who are the main characters from Ramayana?."
"For each character, give the name"
"skills, weapons and a fun fact",
},
],
)
response = chat_completion.choices[0].message.content
print(response)Output
#Sample Output:
These characters form the core of the Ramayana, and their stories and interactions drive the plot of the epic.
1. Rama:
- Food skills: Rama is known for his love of fruit and sweets, particularly mangoes and Indian desserts like halwa.
- Weapon: Rama's weapon of choice is the bow and arrow, known as the divine bow named Sharanga.
- Fun fact: Rama is often depicted as the perfect embodiment of dharma (righteousness) and is a symbol of virtue and heroism in Hindu mythology.....Using instructor library with pydantic
from openai import OpenAI
from typing import List
import instructor
from pydantic import BaseModel, field_validator
client = instructor.from_openai(OpenAI())
# Define your desired output structure
class Character(BaseModel):
name: str
fun_fact: str
weapons: List[str]
skills: List[str]
class Characters(BaseModel):
characters: List[Character]
@field_validator("characters")
@classmethod
def validate_characters(cls, v):
if len(v) < 10:
raise ValueError(f"The number of characters must be at least 10, but it is {len(v)} character")
return v
response = client.chat.completions.create(
model="gpt-3.5-turbo-0125",
messages=[
{"role": "user", "content": "Who are the main characters from Ramayana?."
"For each character, give the name"
"skills, weapons and a fun fact",
},
],
response_model = Characters,
max_retries = 4,
)
from pprint import pprint
pprint(response.model_dump())#Sample Output:
{'characters': [{'fun_fact': 'Rama is considered the seventh avatar of the god '
'Vishnu',
'name': 'Rama',
'skills': ['Archery', 'Leadership'],
'weapons': ['Bow', 'Arrow']},
{'fun_fact': 'Sita is the wife of Rama and an embodiment of '
'purity and sacrifice',
'name': 'Sita',
'skills': ['Patience', 'Devotion'],
'weapons': []}, ....Function Calling give us structured output and a way to interact to external tools, such as booking flights or fetching weather data. This can be especially useful when integrating AI into real-world applications.
tools = [
{
"type": "function",
"function": {
"name": "get_weather_forecast",
"description": "Provides a weather forecast for a given location and date.",
"parameters": {
"type": "object",
"properties": {"location": {"type": "string"}, "date": {"type": "string"}},
"required": ["location", "date"],
},
},
},
{
"type": "function",
"function": {
"name": "book_flight",
"description": "Book a flight.",
"parameters": {
"type": "object",
"properties": {
"departure_city": {"type": "string"},
"arrival_city": {"type": "string"},
"departure_date": {"type": "string"},
"return_date": {"type": "string"},
"num_passengers": {"type": "integer"},
"cabin_class": {"type": "string"},
},
"required": [
"departure_city",
"arrival_city",
"departure_date",
"return_date",
"num_passengers",
"cabin_class",
],
},
},
},
]
from openai import OpenAI
from datetime import date
import json
client = OpenAI()
chat_completion = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": f"Today's date is {date.today()}"},
{
"role": "user",
"content": """This coming friday, I am planning to go to New delhi from bengaluru
I will be with my friend xyz. We will be back on monday morning. Let me know what should i pack according to weather.
Also send flight tickets to my email address [email protected]
1.Book a flight
2.Get weather forecast
3.Send email""",
}
],
tools=tools,
)
for tool in chat_completion.choices[0].message.tool_calls:
print(f"function name: {tool.function.name}")
print(f"function arguments: {json.loads(tool.function.arguments)}")
print()# Sample Output:
function name: book_flight
function arguments: {'departure_city': 'Bengaluru', 'arrival_city': 'New Delhi', 'departure_date': '2025-02-09', 'return_date': '2025-02-12', 'num_passengers': 2, 'cabin_class': 'Economy'}
function name: get_weather_forecast
function arguments: {'location': 'New Delhi', 'date': '2025-02-09'}Conclusion
LLMs are a powerful tool for natural language processing and can be applied in various ways, from text prediction to structured output generation. Experimenting with these models has given me a deeper understanding of their capabilities and how they can be integrated into real-world applications.